
RESEARCH
>Target Sound Extraction
Target Sound Extraction

Imagine yourself in a bustling café, eager to hear your friend's speech amid the mixture of music, keyboard clatter, and ambient noise. Your brain effortlessly filters through these sounds, focusing solely on your friend's speech, aided by clues like their appearance and direction. What if we could train a deep learning model to do the same? Our research is dedicated to harnessing the potential of deep learning algorithms to precisely extract a specific sound from a complex audio mixture, regardless of its composition.
We're pushing the boundaries of sound extraction by leveraging advanced neural network techniques. Our goal is to develop robust models capable of isolating a target sound amidst a variety of sounds, even in challenging real-world environments with background noise and reverberation. In our recent work, we introduced a Transformer-based model designed specifically for extracting reverberant sounds.
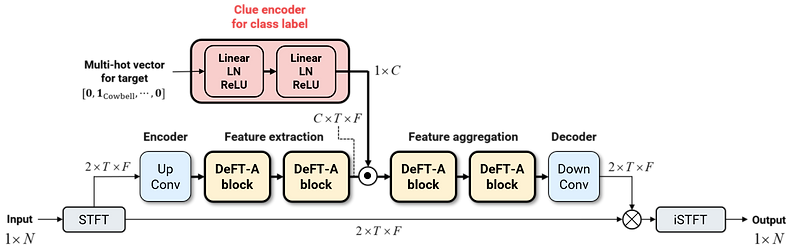
Proposed Model Architecture
Our approach builds on the Dense Frequency-Time Attentive Network (DeFT-AN) architecture, originally developed for speech enhancement tasks. This architecture generates a complex short-time Fourier transform (STFT) mask to separate clean speech from noisy, reverberant mixtures. To make DeFT-AN compatible with the target sound extraction task, we modify its architecture such that the embedding vector for the target class label can be fused in the middle of sequentially connected DeFT-A blocks constituting DeFT-AN.
The figures below illustrate our model architecture and the results of extracting reverberant target sounds, showcasing the effectiveness of our approach. We continue to refine our Transformer-based models to meet the challenges of real-world sound extraction using multiple clues.

Audio clips for demonstrations